I am a third-year Ph.D. student at Stanford CS, co-advised by James Zou and Stefano Ermon. I received my B.S. in Math and CS at Yuanpei College, Peking University, co-advised by Liwei Wang and Di He. During my undergrad, I was fortunate to work with Jacob Steinhardt and Simon S. Du as a visiting researcher. I also collaborated with Ming-Yu Liu as an intern in NVIDIA Cosmos, and Felix Yu in Google Deepmind.
My Ph.D. research aims to advance model capabilities for open problems through post-training and inference-time algorithm design. Specifically, for both text and vision models:
- How do we continuously improve them via post-training, even at superhuman levels?
- How do we scale test-time compute effectively and efficiently?
I believe in the synergy of scalable engineering and principled algorithm design. This philosophy is grounded in my early research on deep learning foundations and AI for science. Feel free to reach out if you are interested in my research or simply want to chat.
News
- (June 2026) I will be giving a few talks on SimpleTES. Please check out our blog for our thoughts, and let me know if you are interested in the work!
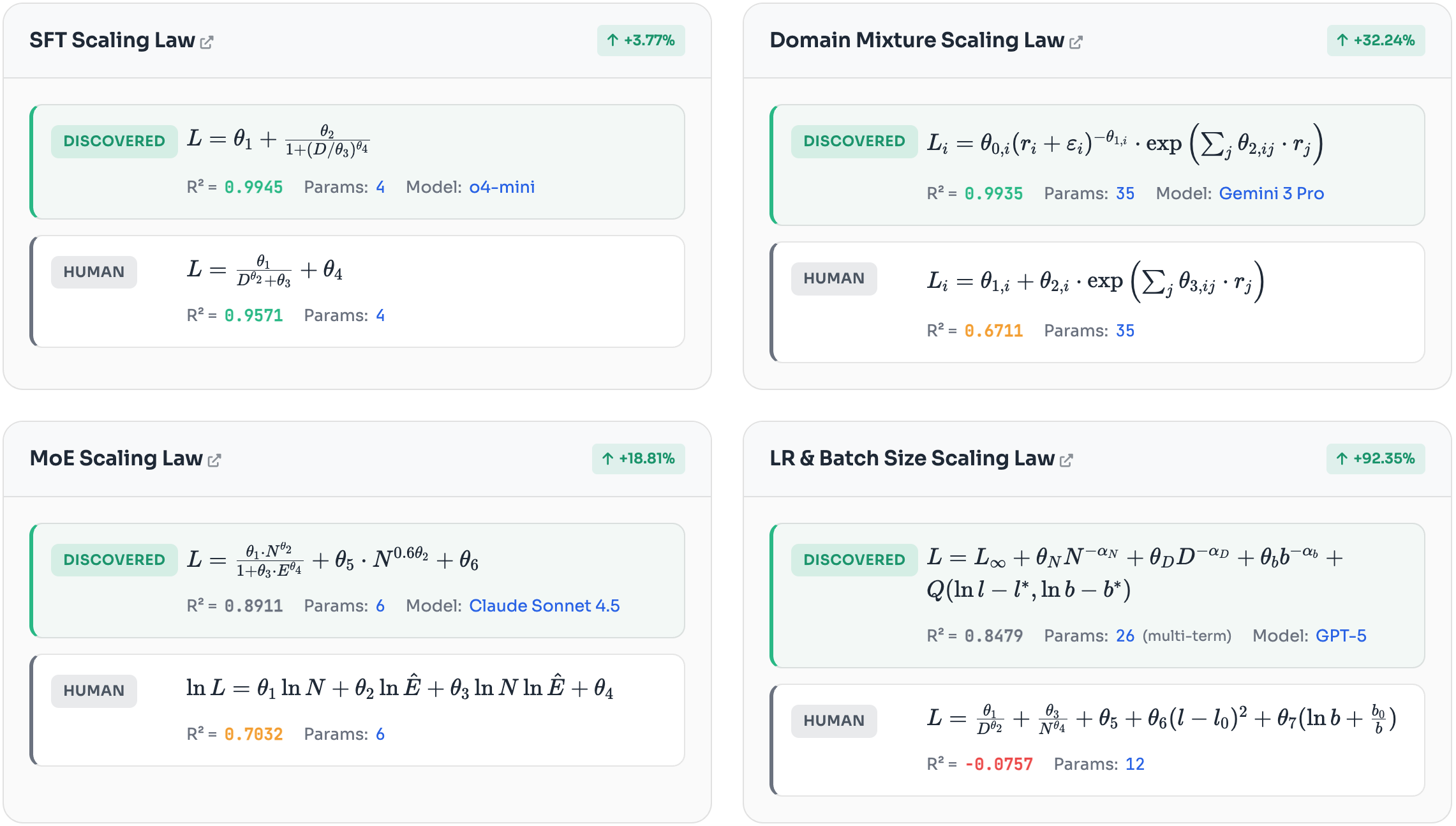
- (May 2026) Check out SimpleTES, our new work on strategically scaling evaluation-driven discovery loops — achieving state-of-the-art on 21 problems across six domains with open-source models. See paper, code, and X.
- (Apr. 2026) I passed my Ph.D. qualifying exam at Stanford!
- (Feb. 2026) InfoTok (Oral) and Scaling Law Discovery accepted by ICLR 2026. See you in Rio de Janeiro!
Selected Publications





Invited Talks
Recursive Superintelligence, June 2026
SimpleTES: A General Framework for Strategically Scaling Evaluation-Driven Discovery LoopsLightning Talk at AI Agents for Discovery in the Wild Workshop (CAIS 2026), May 2026
SimpleTES: A General Framework for Strategically Scaling Evaluation-Driven Discovery LoopsByteDance Seed, May 2026
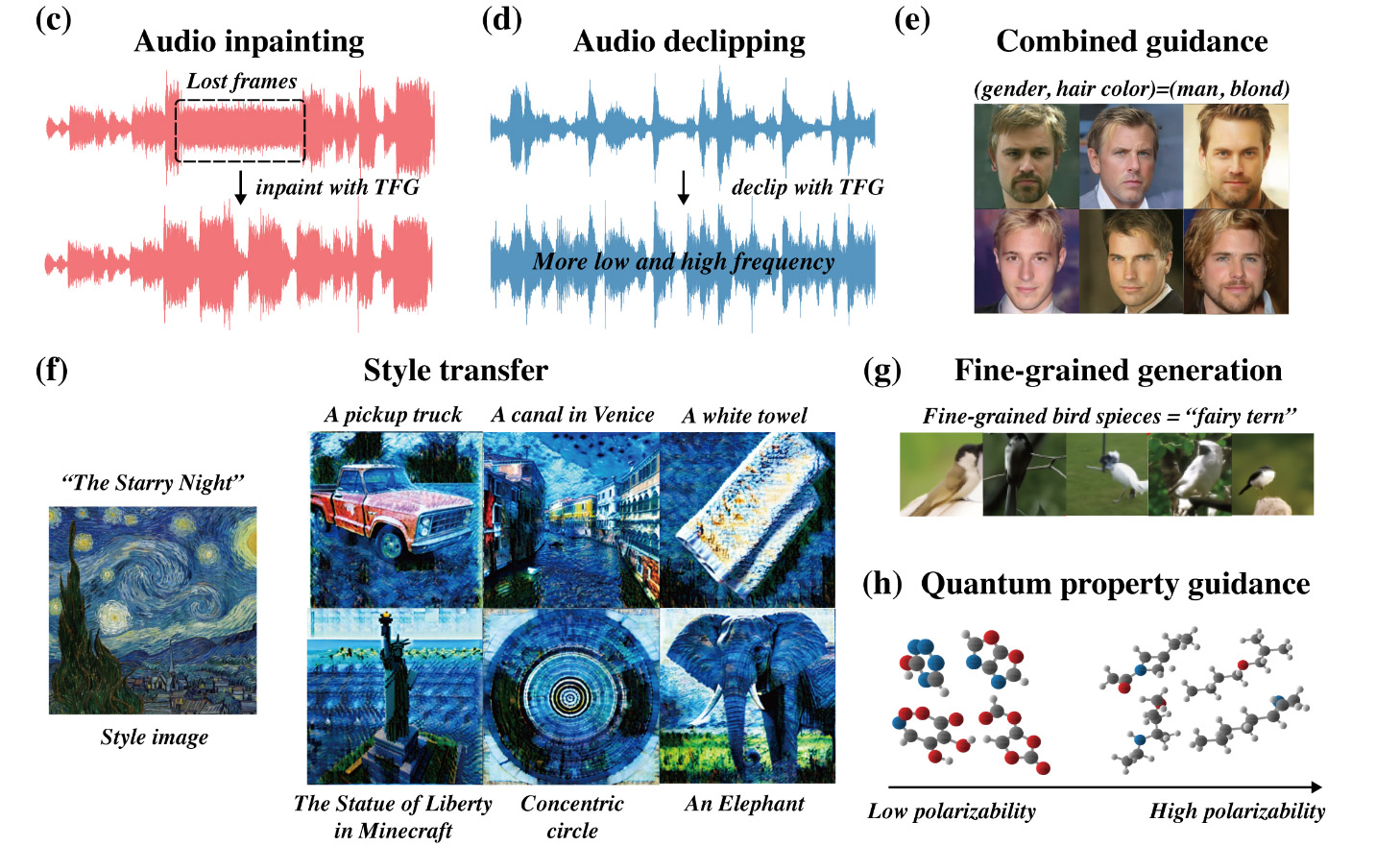
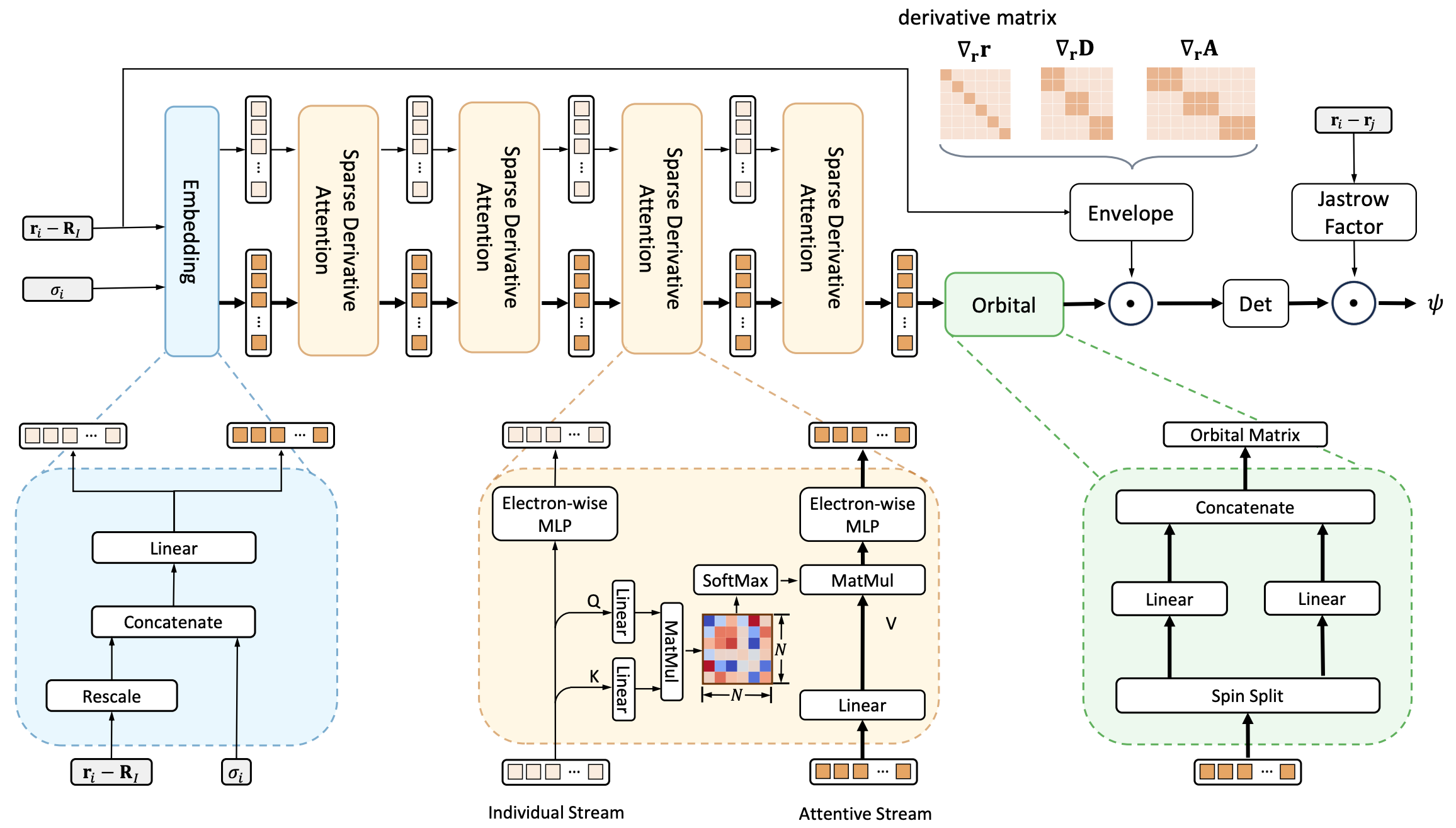
Data-regularized Reinforcement Learning for Diffusion Models at Scale
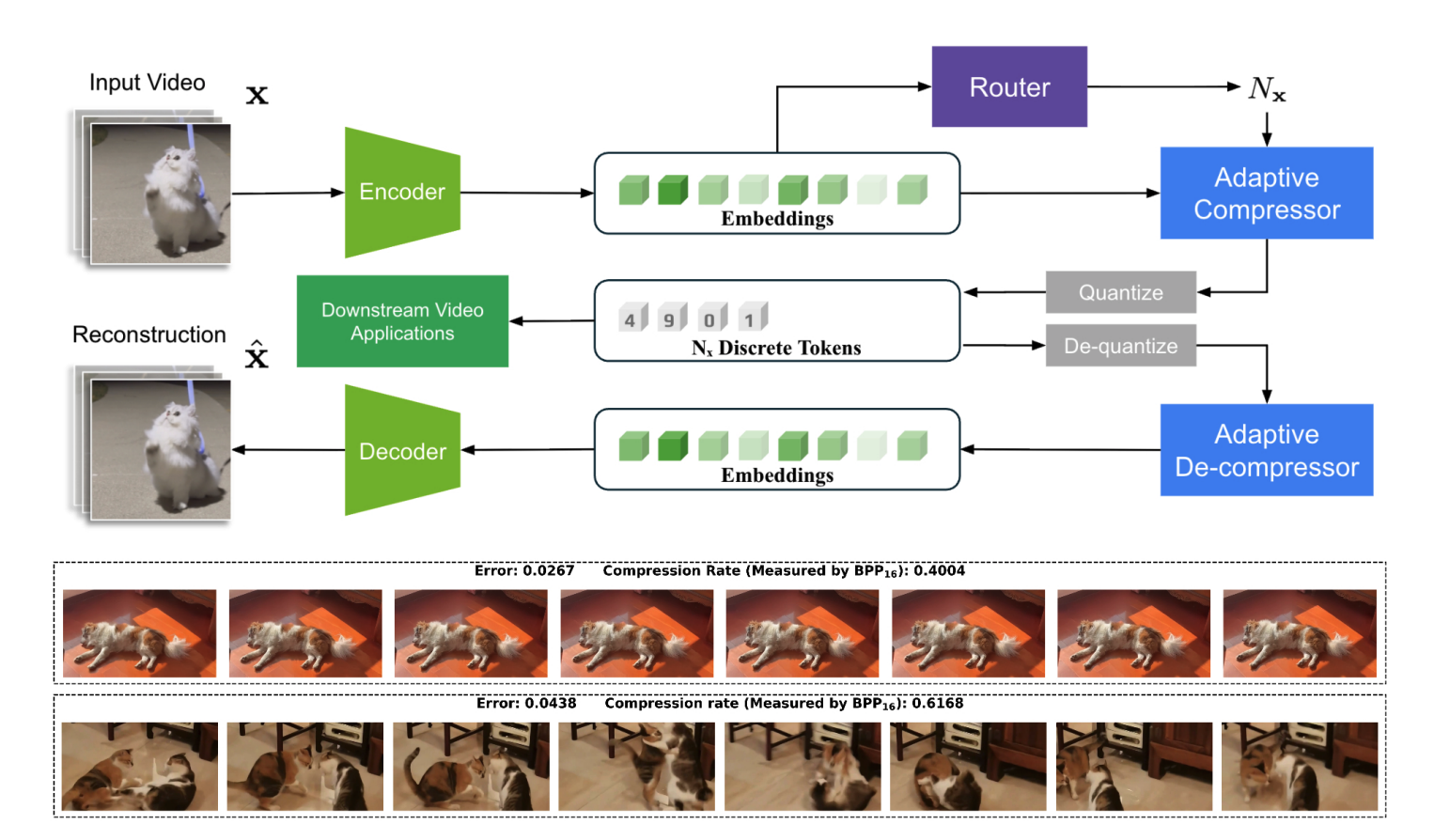
InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic CompressionCalTech, Feb. 2026
Data-regularized Reinforcement Learning for Diffusion Models at ScaleByteDance Seed, Feb. 2026
Data-regularized Reinforcement Learning for Diffusion Models at ScaleNVIDIA Research, Oct. 2025
Data-regularized Reinforcement Learning for Diffusion Models at ScaleNVIDIA Research, July 2025
InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic CompressionGoogle Research, March 2025
Efficient and Asymptotically Unbiased Constrained Decoding for Large Language ModelsThe Hong Kong University of Science and Technology, Dec. 2023
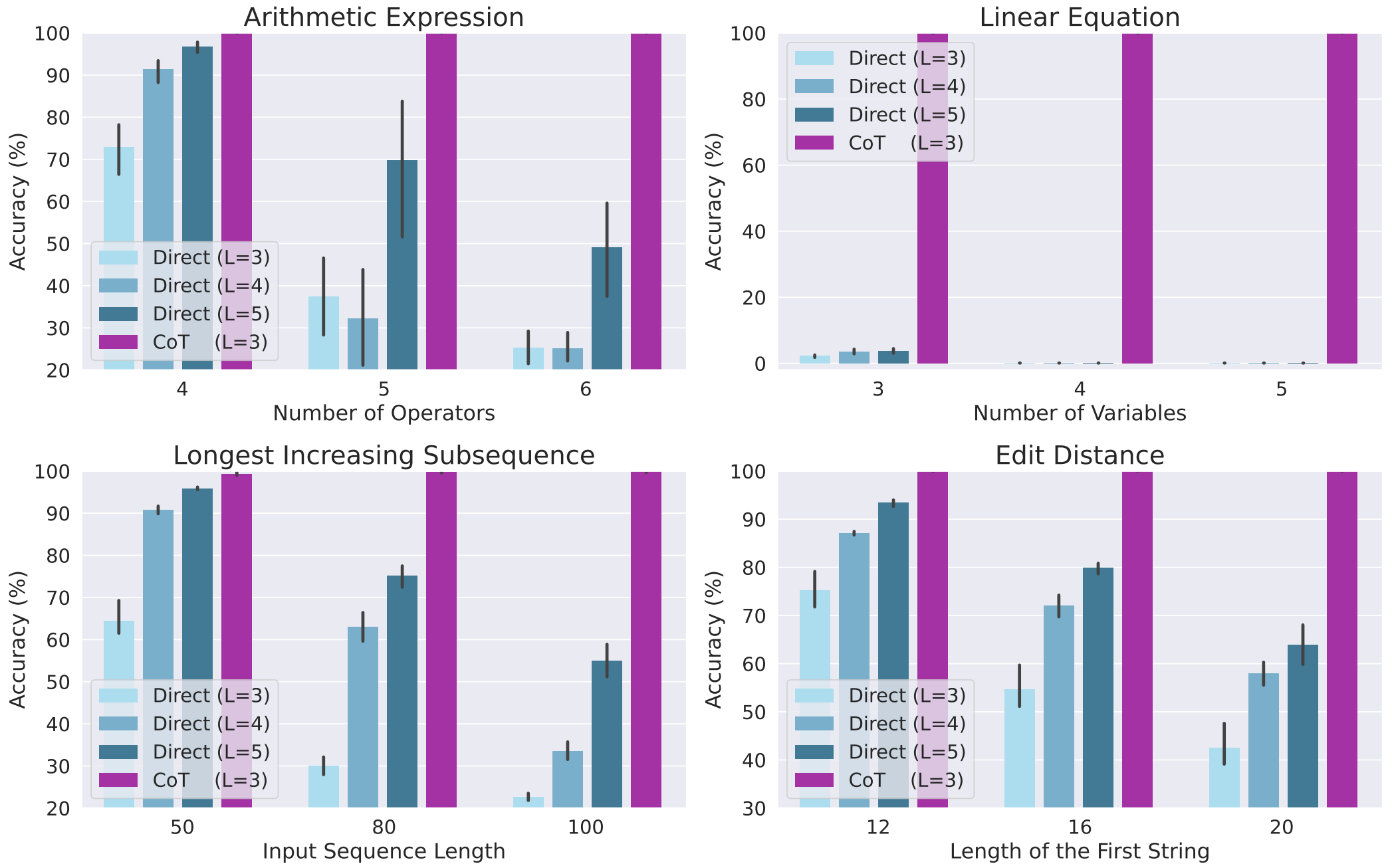
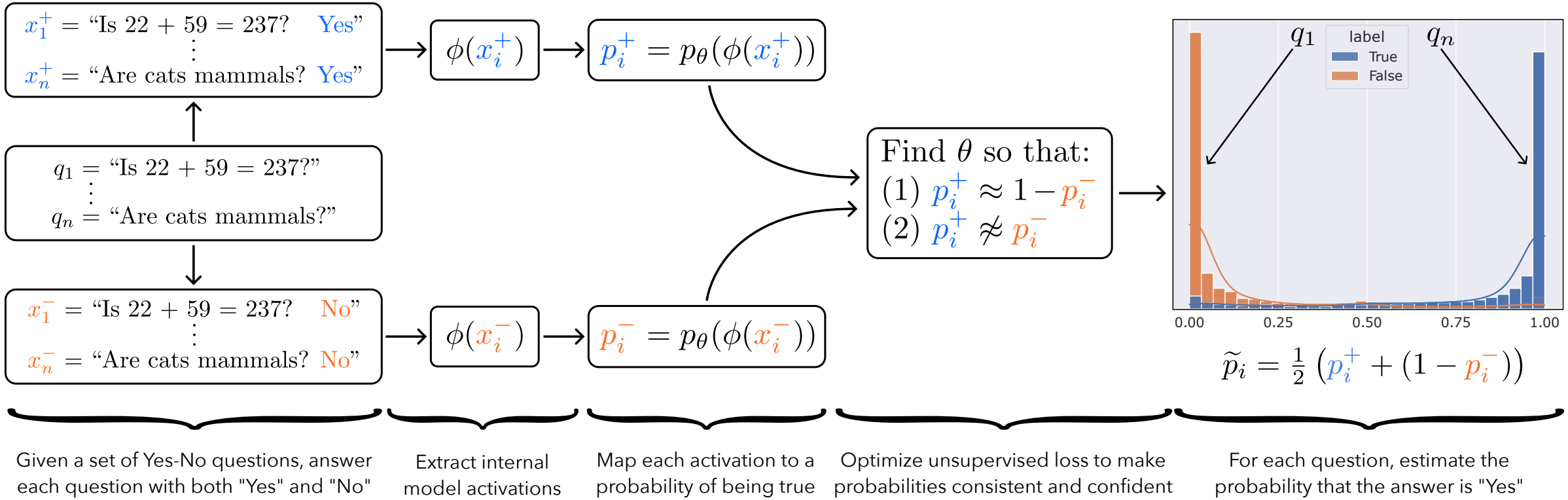
Towards Revealing the Mystery behind Chain of Thought: A Theoretical PerspectiveGoogle Brain, May 2023
Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective
Professional Services
- Reviewer: NeurIPS (2022-2025), ICLR (2024-2026), ICML (2024-2025), AISTATS (2023, 2025, Top Reviewer), ICCV (2025), EMNLP (2022)
Selected Awards
- Weiming Scholar of Peking University (1%), 2023
- Person of the Year of Peking University (10 people/year), 2021
- May 4 scholarship (1%, Rank 1), 2021
- National scholarship (1%, Rank 2), 2019
- Leo Koguan scholarship (1%), 2020
- Merit student pacesetter (2%), 2019
- Chinese Mathematical Olympiad (First Prize, Rank 7 in China), 2017
Miscellaneous
I spend most of my free time on photography, scuba diving (check the avatar!), and soccer (Palo Alto Adult Soccer League)!