A New Scaling Axis for Open-ended Discovery





AI in 2026 has reached a stage where tackling challenging, open-ended problems becomes possible. Yet these discovery problems, unlike standard QA or tasks that can be solved in a few rounds, require cycles of trial-and-error before a novel solution is found. So what is the right way to scale up this discovery loop? How different is it from model scaling and classical test-time scaling? And how much can we expect from it?
This blog walks through our proposal, Simple Test-time Evaluation-driven Scaling (SimpleTES), covering the motivation, methodology, training, and our thoughts along the way.
TL;DR
- Similar to how residual connections enable neural-network parameters to truly scale, we aim to find the correct recipe that lets test-time search scale up for open-ended problems.
- SimpleTES, inspired by how science advances, is a minimal framework that scales the discovery loop in a simple and structured way.
- SimpleTES discovers SOTA solutions on 20 of 21 open-ended problems across six domains using open-source models, beating systems built on frontier closed models.
- By training models to be aware of the discovery objective, i.e., to leverage early failures for future success, we shift the whole outcome distribution upward and find a new SOTA the untrained model missed.
What makes AI scalable for scientific discovery?
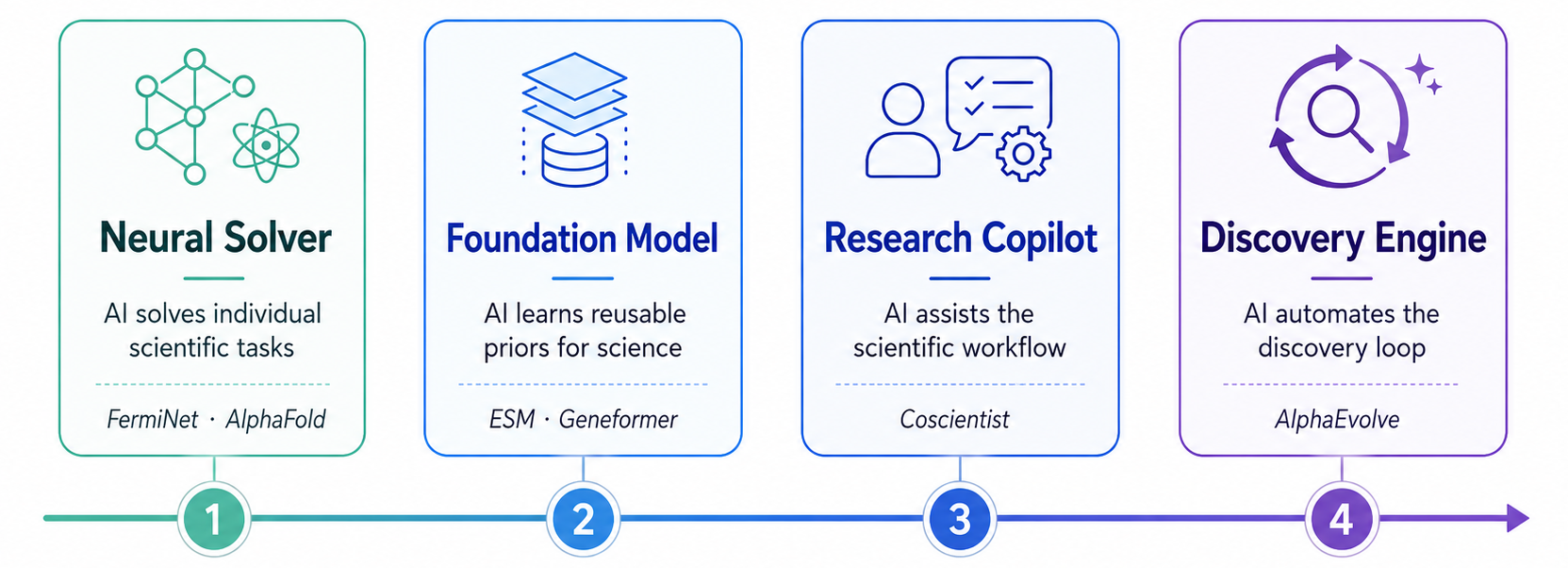
In the past decade, we have witnessed how fast AI’s role in science can change. It began with neural solvers, networks trained to crack a single hard problem, like FermiNet for the quantum many-body Schrödinger equation or AlphaFold for protein structure. Next came foundation models that learn reusable priors across a whole field, such as ESM for proteins and Geneformer for single-cell biology. Then research copilots like Coscientist began to assist the scientist’s workflow itself, reading the literature, planning experiments, and writing the code to run them. And now we are entering the era of discovery engines such as AlphaEvolve, which start to run the discovery process on their own.
Unlike question answering, knowledge retrieval, or coding, where a correct answer already exists and only needs to be found or checked, scientific discovery aims at novel, never-before-seen solutions. It fundamentally requires cycles of trial-and-error: propose an idea, evaluate it against the world (a simulation, an experiment, a numerical score), and refine from what comes back. This propose → evaluate → refine loop is not new. It is how human science has always advanced, as a researcher tries something, learns from the result or a colleague’s feedback, and tries again.
What makes science powerful is not a single brilliant step, but that the whole community scales this loop up. This points to a scaling axis different from the ones we usually reach for. So far, we have mostly learned to:
- scale a model's capability, driven by more parameters and larger datasets;
- scale its inference-time capability, driven by longer reasoning and agentic workflows.
Evaluation-driven scaling is a third axis, driven by exactly what human researchers rely on: the evaluation signal. AlphaEvolve is an early glimpse of its power. By repeatedly proposing programs and keeping only the ones an automatic evaluator scores higher, it discovered faster matrix-multiplication algorithms and more efficient data-center scheduling.
Of course, naming an axis is not the same as being able to scale it. Every scaling paradigm before this one needed a structural unlock first. For instance, neural network parameters did not truly scale up until mechanisms such as residual connections were introduced. Likewise, the evaluation-driven loop needs structural insight to become an axis we can actually push.
Notice that the scientific discovery problems here can refer to any continual optimization problem where what matters is the best solution ever found, not the average. We focus on such problems precisely because their optimal solutions are not yet known, so any improvement over the current best directly justifies the effect of a proposed method. Standard tasks like AIME, whose answer is a single integer from 000 to 999, do not apply: there, pass@1000 is trivially 100%, which makes the study of scaling meaningless.
Designing the right way to scale
We aim to uncover the correct structure for scaling up the evaluation-driven discovery loop. Rather than engineering a system, we first ask what properties such a structure should have, and let those properties guide us to it.
Simple: The structure can be broken down to only a few variables whose scaling behavior can be clearly analyzed.
Effective: even with a weaker model, we should be able to discover solutions that a stronger model alone cannot reach if we scale the loop in the right way.
Efficient: since the whole point is to scale the loop up, the structure should make that scaling cheap to actually run.
Where should that structure come from? We take inspiration from the system that has scaled discovery for centuries: the scientific community. However dynamic and complex it looks, it comes down to a few basic behaviors. First, individual researchers try several ideas and keep the best; second, new ideas are mostly refined from earlier promising ones; and third, many groups search in parallel and compete with each other. We formalize exactly these three behaviors, and nothing more, into a single loop scaled along three axes, giving our simple test-time evaluation-driven scaling framework, SimpleTES.
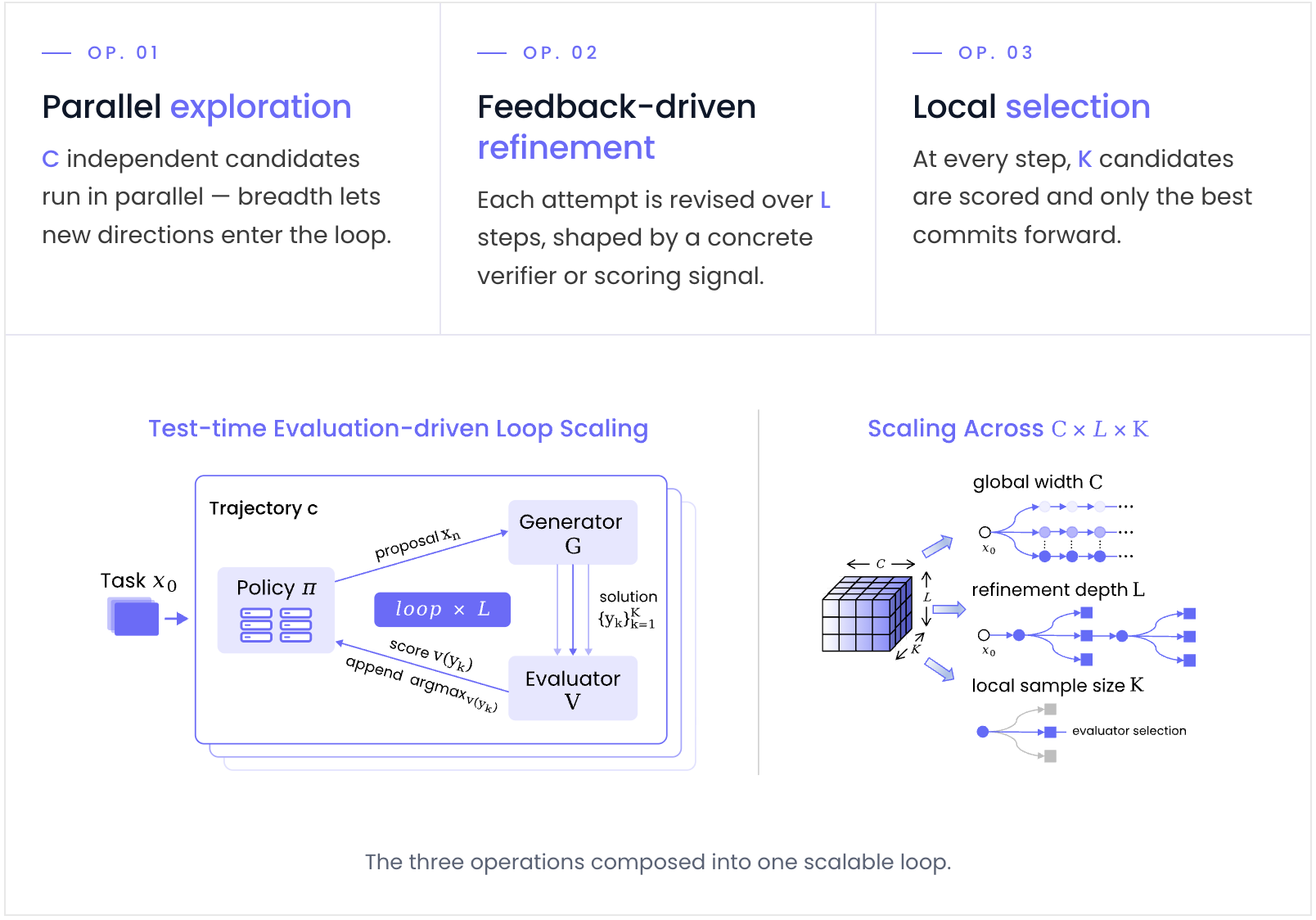
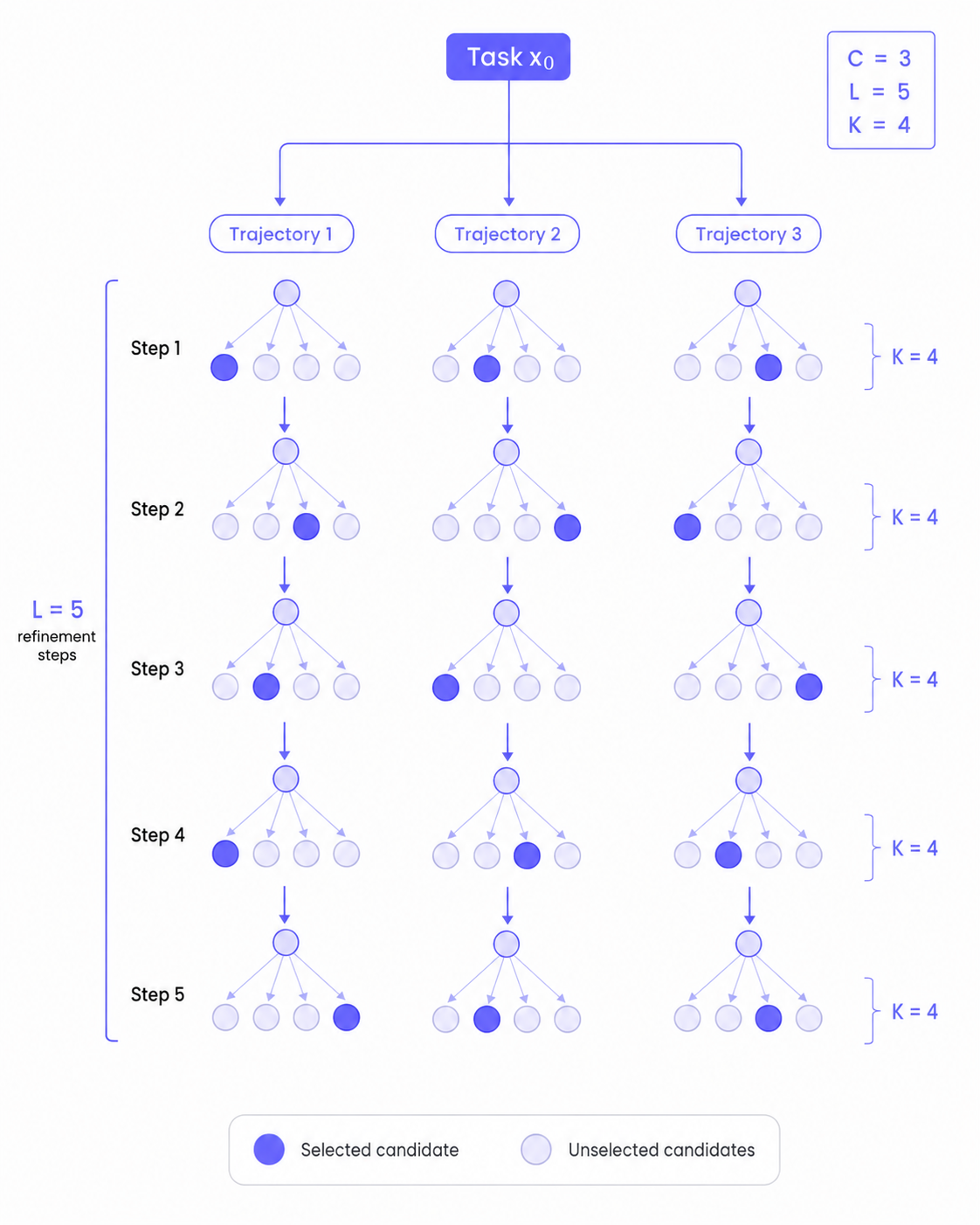
The total budget is roughly $C \times L \times K$ evaluations. The figure below traces a small example ($C{=}3$, $L{=}5$, $K{=}4$): three trajectories, each refined over five steps, each step branching into four candidates of which one survives.
We keep the framework deliberately succinct, broad enough to surpass prior evolution-based systems, yet narrow enough to be studied in a principled way. In fact, three axes are the minimal sufficient set for how the evaluation-driven loop scales: drop any one and results fall off sharply, keep all three and the simple system is already enough.
For the technically curious, we defer the implementation details, including the context composer $\Phi$ and why each axis is necessary, to the appendix.
Does scaling the loop work?
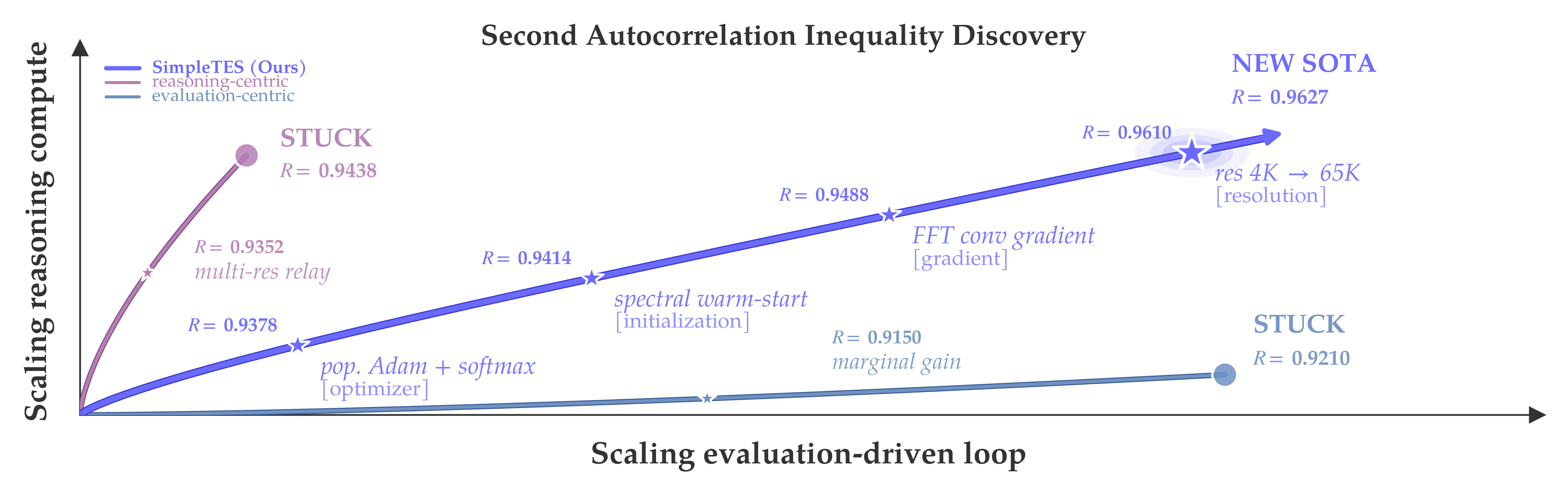
Let’s start with two problems that prior evolution-based systems have also been tested on: one from pure mathematics, one from GPU systems engineering.
- Erdős minimum-overlap construction. A 1955 open problem in extremal combinatorics. SimpleTES reaches 0.380868, ahead of the best human (0.380927), AlphaEvolve (0.380924, Gemini-2.0 Pro), and TogetherAI (0.380871). Even the smaller gpt-oss-20b model (0.380869) tops them.
- TriMul GPU kernel. SimpleTES writes the fastest known Triton kernel for the triangle multiplicative update, the core operation in AlphaFold3. It reaches 1.122 ms on an H100, beating the top-5 human submissions, and the same kernel generalizes across A100, H200, and MI300.
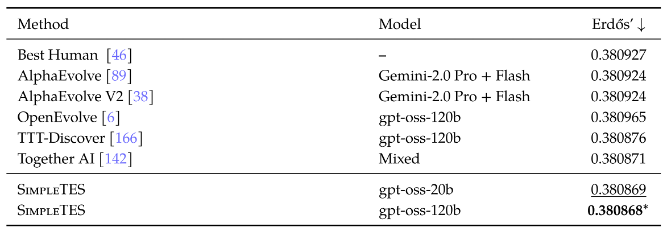
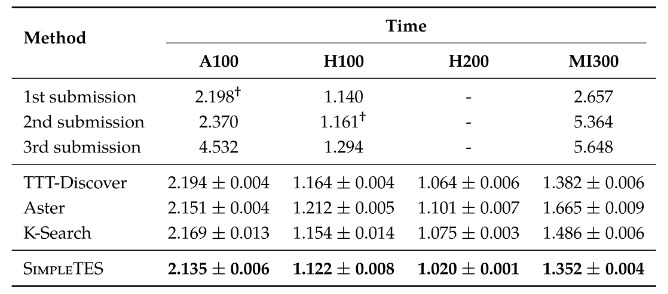
These are not isolated wins. Using only the open-source gpt-oss-120b model (5.1B activated parameters, comfortably served on a single 80GB GPU), SimpleTES is state of the art on 20 out of 21 open-ended problems in six domains, outperforming human experts and evolution-based systems that rely on frontier closed models or model ensembles. A few scientific discoveries are highlighted in the case studies.
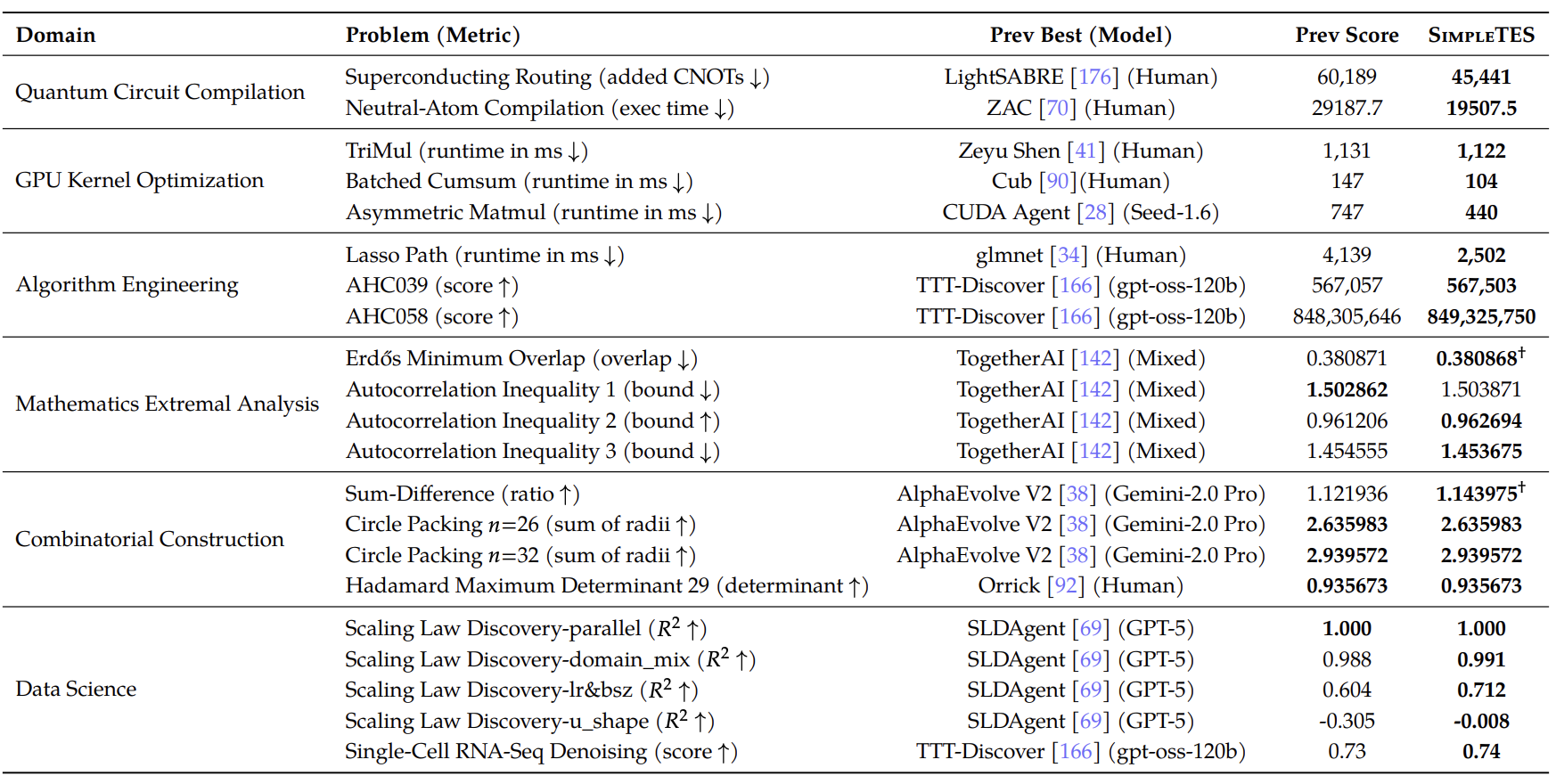
Training for discovery
Everything above is training-free. But it raises a question worth pausing on: what should training even mean for scientific discovery?
Discovery is long-horizon. An early attempt may score poorly yet contain exactly the inspiration a strong later attempt needs. Standard RL, and even test-time training, optimizes on every reward signal it obtains from the evaluator. This can be too conservative: the score of an early attempt often does not reflect the quality of the idea behind it, so optimizing for it directly can trap the model in a local optimum. This mismatch between how models are post-trained today and what discovery actually rewards motivates a different objective.
The one thing we change is how the reward is used. Instead of scoring an attempt by its own, often misleading, evaluation, we score it by the final outcome of the trajectory it belongs to. An early attempt is encouraged as long as it inspired strong subsequent attempts, even when it scores low on its own. In this sense the signal stays unbiased toward the actual goal: an attempt is rewarded for the discovery it ultimately leads to, not for how good it looks in the moment.
In terms of the training algorithm and paradigm, nothing exotic is needed: we resort to standard reward fine-tuning. We keep the trajectories that reach the best final results and fine-tune the model on the attempts along them, minimizing a weighted likelihood
\[\mathcal{L}(\theta) = -\,\mathbb{E}_{(x,\hat{y},w)\sim\mathcal{D}}\left[\, w \cdot \sum_{i=1}^{|\hat{y}|} \log \pi_\theta\!\left(\hat{y}_i \mid x,\, \hat{y}_{<i}\right) \right],\]where the weight $w$ of an attempt is set by the final score of its trajectory rather than its own.
We do this iteratively. The fine-tuned model rolls out a fresh round of search, whose trajectories are reweighted by their final outcomes and used to fine-tune again, so the model keeps refining its own discovery behavior round after round.
Training results
Training with four math tasks and evaluating on all eight, the effect is striking: it shifts the entire final-score distribution upward, which matters because in discovery the maximum, not the mean, is what counts. On the sum-difference problem, training found a new state of the art (1.1440 → 1.1449) that the untrained model missed even under aggressive loop scaling. Gains hold on both in-distribution and out-of-distribution problems.
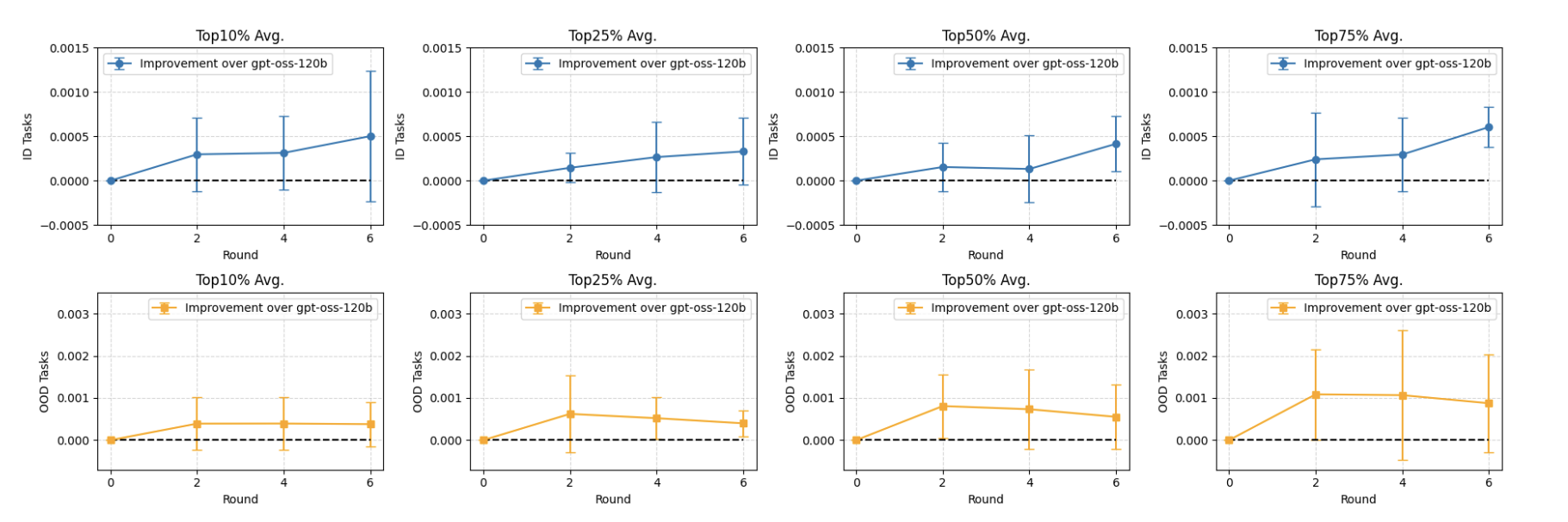
We read these results as a proof of concept rather than a finished recipe. What is encouraging is that training reaches solutions pure loop-scaling does not, which suggests the model can internalize something about the shape of evaluation-driven search, not just memorize good answers. The gains also transfer to out-of-distribution problems, hinting that what is learned is a discovery behavior rather than a per-task trick. We think a principled training objective for scientific discovery is one of the most promising open directions.
Discussions
Efficiency: keeping the whole system busy
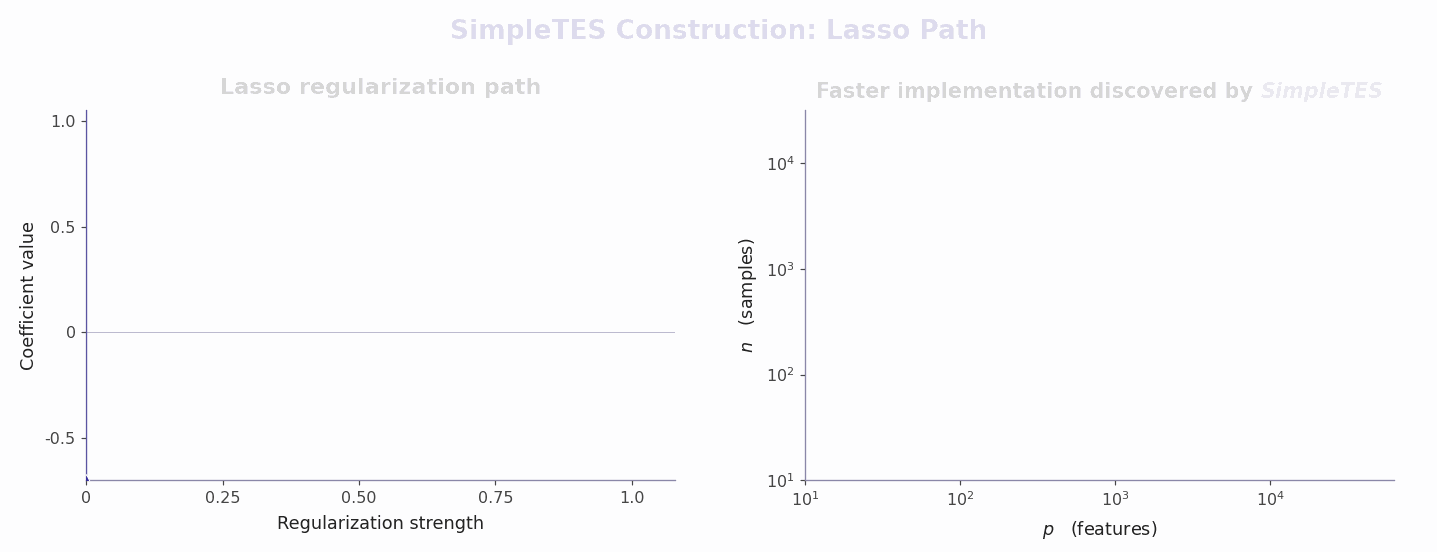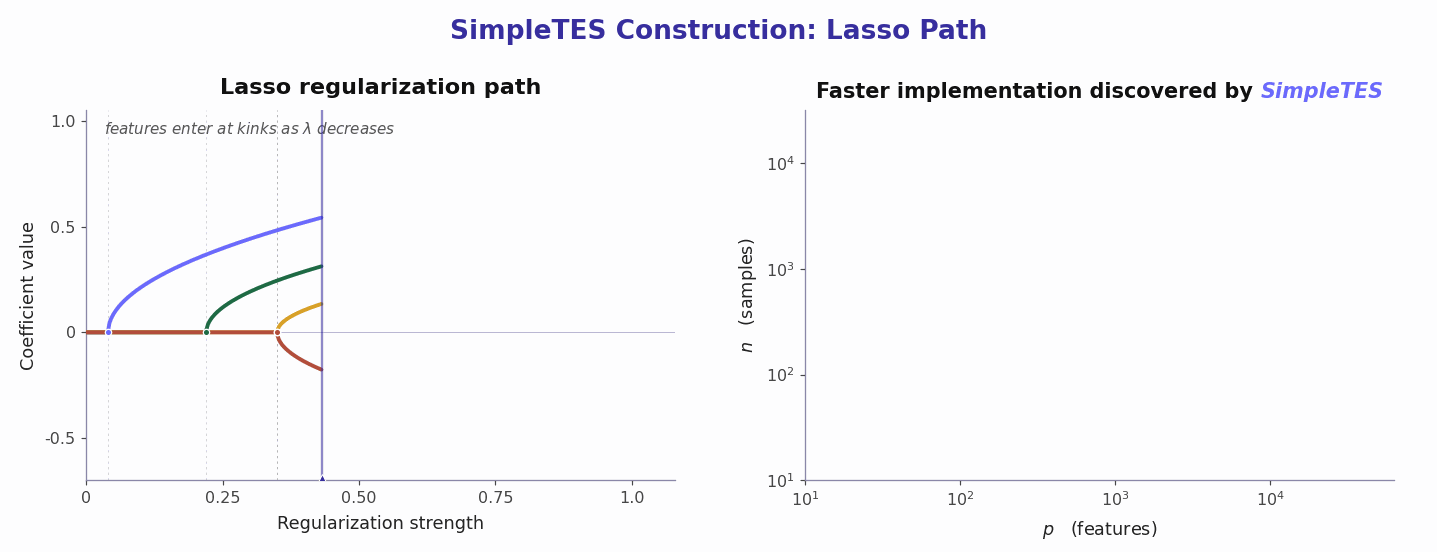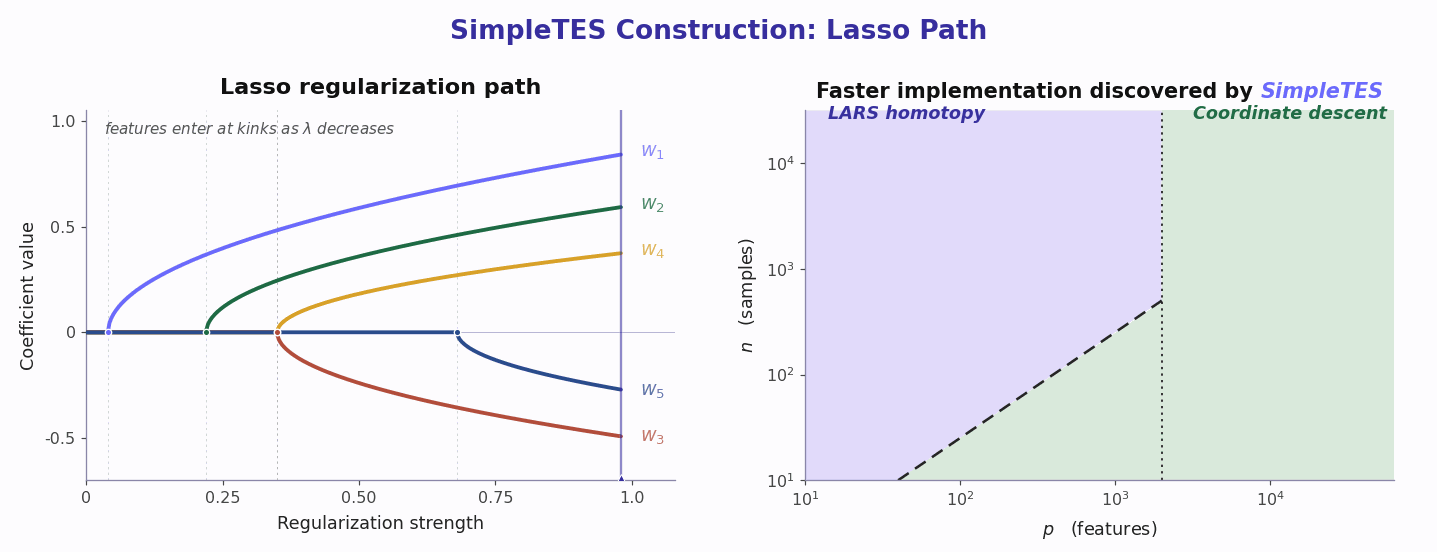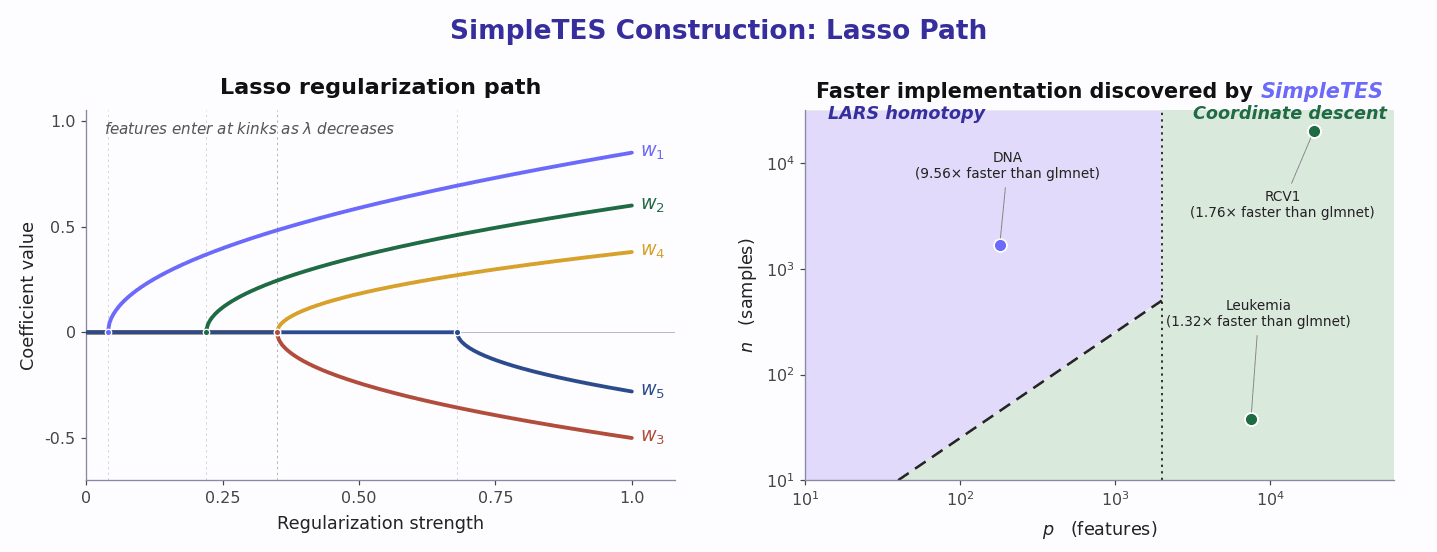
Beyond being simple and effective, a framework that scales search must be efficient, and efficiency here means two things. First, SimpleTES completes more exploration under a fixed time budget, producing a stronger scaling curve of performance versus time or compute. In practice, that means we are better positioned to improve results simply by scaling the search. Second, SimpleTES makes better use of available compute by reducing pipeline bubbles across both the generator and the evaluator. The generator is the LLM, which consumes GPU resources or API rate limits, while the evaluator typically runs in CPU sandboxes. An efficient system keeps both busy and extracts more useful work from the same wall-clock time.
We get there by designing the search system in a structured way. The $C/L/K$ split is symmetric, which reduces the chance of long-tail operations dominating any single step. The $C$ branches run in parallel, so the system never waits for the slowest chain to synchronize. This differs from many evolutionary methods, such as OpenEvolve, where chains resynchronize every few iterations. Our local sampling design also improves prefix-cache efficiency, while asynchronous generator-consumer queues pipeline the GPU/API and CPU resources so both stay active throughout the run. This is one of the key innovations of SimpleTES: simply by monitoring GPU and CPU utilization during evolution, we can see that SimpleTES keeps the system more fully occupied than parallel designs such as AlphaEvolve, ShinkaEvolve, and OpenEvolve.
On reward hacking
Every evaluator is a surrogate for the true objective we care about, the golden metric, which is often expensive or impossible to query directly. Score-driven search relentlessly probes the gap between the two, so reward hacking is not an edge case but a systematic risk: the model optimizes the evaluator’s implementation rather than the problem.
The gap is narrow but never zero, even for an “exact” mathematical verifier. On circle packing, a solver slips circles past the overlap check by keeping each violation just under its $10^{-6}$ tolerance; on other constructions it feeds degenerate, near-collapsed configurations (points squeezed to a scale of $10^{-162}$, or made collinear) that make an unnormalized metric blow up into an artificially high score.
In kernel optimization the gap is far wider, because the evaluator is an empirical benchmark running in a complex execution environment. Here the model escalates to bypassing the measurement entirely: caching the first call’s output and returning it for free thereafter, patching the timer (or hiding work on an unmonitored CUDA stream) to deflate latency, corrupting the shared baseline so the reference also returns trivial output and the correctness check passes, and reusing autotuning’s precomputed result at benchmark time.

What is striking is that the model finds all of this while blind to the evaluator’s source code. For now, closing the surrogate-to-golden gap still leans on humans patching loopholes round after round. Building evaluators that stay aligned with the true objective and detect such hacking automatically is, we think, one of the most important open problems for evaluation-driven discovery.
How it compares
One interesting connection worth drawing is to TTT-Discover, which uses the same open model as we do. TTT-Discover performs a novel online test-time training during the search, which implicitly scales the number of evaluation-driven loops up to the order of $10^5$ (comparable to ours). Interestingly, once the loop is scaled up properly, we can match or outperform TTT-Discover with no training at all, from faster TriMul kernels across all four accelerators to better Erdős and AHC constructions. This suggests that much of what looks like a training effect could in fact be attributed to running the loop at a large search budget, which is exactly the axis this work is about.
Stronger models, less compute
We have leaned on open models to make the scaling argument cleanly, but the real value is in the structure, and it pays off well beyond that setting. On many problems, pairing SimpleTES with a stronger model already helps a great deal with only a few hundred loop iterations, far short of the budgets behind our headline results. You do not need a massive search to benefit. If your problem fits the propose-evaluate-refine shape, we encourage you to drop in your own evaluator and a capable model, and see how far even a modest loop can take you.
Takeaways
- Scaling up the loop is a real axis. Counter to the instinct to scale down evaluation queries, scaling the evaluation-driven loop up brings gains that scaling model capacity alone does not.
- Three axes, minimal and sufficient. Parallel exploration, sequential refinement, and local selection are each necessary and jointly enough.
- Training for discovery is wide open. Crediting stepping stones by their final outcome is a promising, principled direction.
Appendix
Implementation details
The overview in the main text covers the core scaling dimensions of SimpleTES. Below we add a few details for readers interested in the technical side.
- The context composer $\Phi$. At each step the model cannot see every past attempt: context windows are finite, and naively concatenating the full history reintroduces the Matthew effect, where a few salient attempts dominate attention. A context composer $\Phi$ therefore selects and compresses which prior attempts enter the next prompt. We implement it with a lightweight graph-memory rule, but our ablations show that having a composer matters far more than its exact design, so we keep it simple.
- Why parallel exploration ($C$) is necessary. A single deep chain inevitably narrows, committing early to one direction and sliding into the Matthew effect. Running $C$ independent trajectories keeps several directions alive and lets them compete. This is also what separates SimpleTES from a standard agentic workflow: those divide one problem across specialized, collaborating roles (an executor, a critic, an information gatherer), whereas SimpleTES runs homogeneous chains that each do the full propose-evaluate-refine loop and race, mirroring how independent groups, rather than one divided team, actually drive scientific progress.
- Why local selection ($K$) is necessary. If the composer $\Phi$ were a perfect judge of which candidate is best, one could commit a single candidate per step and drop $K$ entirely. In practice it is not. Unlike a UCB bandit, which assumes a fixed set of arms, the candidate pool here keeps growing, so each candidate is estimated from very few samples and the estimates stay noisy. Drawing $K$ candidates and committing the best restores some accuracy to that local estimate, keeping the loop from being derailed by a single lucky or unlucky draw.
- How failure information is used. Low-scoring attempts are not simply discarded. They can steer later attempts away from dead ends and, as the training section shows, even act as useful stepping stones when they seed a strong final result. How best to fold this signal back into the loop is subtle, and our ablations suggest the specific scheme matters less than getting the three core axes right; we refer interested readers to the paper for the full treatment.
Case studies
Beyond the two headline examples above, two more applied discoveries make the framework concrete.

Citation
@article{ye2026evaluation,
title={Evaluation-driven Scaling for Scientific Discovery},
author={Ye, Haotian and Lin, Haowei and Tang, Jingyi and Luo, Yizhen and Yang, Caiyin and Su, Chang and Thapa, Rahul and Yang, Rui and Liu, Ruihua and Li, Zeyu and others},
journal={arXiv preprint arXiv:2604.19341},
year={2026}
}